






When I wrote about GitHub Copilot in November 2021, Copilot was one of only a handful of AI code generation technologies available. I tested it as a Visual Studio Code extension. At the time, Copilot didn’t always generate good, correct, or even running code, but it was still somewhat useful. The great promise behind Copilot (and other code generators that use machine learning) is that it was designed to improve over time, both by incorporating user feedback and by ingesting new code samples into its training corpus.
As of May 2023, there are hundreds of “AI” or “code generation” extensions available for Visual Studio Code alone. Several of these might save you some time while coding, but if you believe their generated code without reviewing, testing, and debugging it, I have a bridge to sell you.
 IDG
IDG
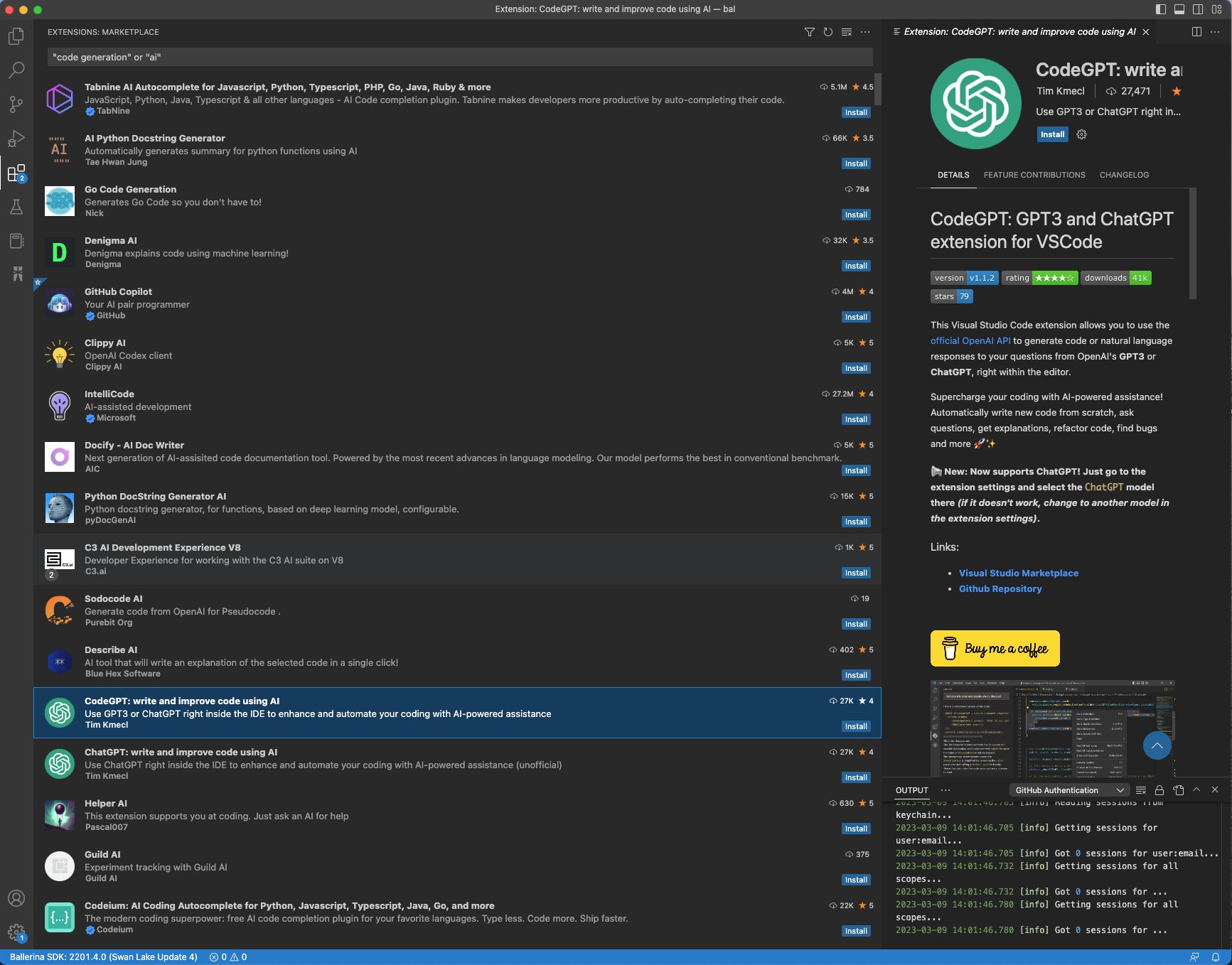
Hundreds of Visual Studio Code extensions in the marketplace promise “code generation” or “AI,” but only a fraction of them actually generate code based on machine learning.
One promising development in this area is that several tools have automatic generation of unit tests. Generating unit tests is a much more tractable problem than generating general-purpose code—in fact, it can be done using simple patterns—but you’ll still have to review and run the generated tests to see whether they make sense.
In the balance of this article, I’ll offer a brief history of language models, before surveying the state-of-the-art large language models (LLMs), such as OpenAI’s GPT family and Google’s LaMDA and PaLM, used for text generation and code generation today. We’ll finish with a quick tour of 10 code generation tools, including Amazon CodeWhisperer, Google Bard, and GitHub Copilot X.
A brief history of AI models for text generation
Language models go back to Andrey Markov in 1913. That area of study is now called Markov chains, a special case of Markov models. Markov showed that in Russian, specifically in Pushkin’s Eugene Onegin, the probability of a letter appearing depends on the previous letter, and that, in general, consonants and vowels tend to alternate. Markov’s methods have since been generalized to words, to other languages, and to other language applications.
Markov’s work was extended by Claude Shannon in 1948 for communications theory, and again by Fred Jelinek and Robert Mercer of IBM in 1985 to produce a language model based on cross-validation (which they called deleted estimates), and applied to real-time, large-vocabulary speech recognition. Essentially, a statistical language model assigns probabilities to sequences of words.
To quickly see a language model in action, type a few words into Google Search, or a text message app on your smartphone, and allow it to offer auto-completion options.
In 2000 Yoshua Bengio et al. published a paper on a neural probabilistic language model in which neural networks replace the probabilities in a statistical language model, bypassing the curse of dimensionality and improving the word predictions (based on previous words) over a smoothed trigram model (then the state of the art) by 20% to 35%. The idea of feed-forward, auto-regressive, neural network models of language is still used today, although the models now have billions of parameters and are trained on extensive corpora, hence the term “large language models.”
As we’ll see, language models have continued to get bigger over time to make them perform better. There are costs to this, however. The 2021 paper On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? by Emily Bender, Timnit Gebru, et al. questions whether we are going too far with this trend. The authors suggest, among other things, that we should weigh the environmental and financial costs first, and invest resources into curating and carefully documenting data sets rather than ingesting everything on the web.
Large language models for text generation
The recent explosion of large language models was triggered by the 2017 paper Attention is All You Need, by Ashish Vaswani et al. of Google Brain and Google Research. That paper introduced “a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.” Transformer models are both simpler than and superior to recurrent and convolutional models. They also require significantly less time to train.
ELMo
ELMo is a 2018 deep contextualized word representation from AllenNLP (see ELMo paper) that models both complex characteristics of word use (e.g., syntax and semantics) and how these uses vary across linguistic contexts (i.e., to model polysemy). The original model has 93.6 million parameters, and was trained on the One Billion Word Benchmark.
BERT
BERT is a 2018 language model from Google AI Language based on the company’s Transformer (2017) neural network architecture (see BERT paper). BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. The two model sizes used in the original paper were 100 million and 340 million total parameters. BERT uses masked language modeling (MLM) in which ~15% of tokens are “corrupted” for training. It was trained on English Wikipedia plus the Toronto Book Corpus.
T5
The 2020 Text-To-Text Transfer Transformer (T5) model from Google (see T5 paper) synthesizes a new model based on the best transfer learning techniques from GPT, ULMFiT, ELMo, and BERT and their successors, using a new open-source, pre-training data set called the Colossal Clean Crawled Corpus (C4). The standard C4 for English is an 800 GB data set based on the Common Crawl data set. T5 reframes all natural language processing tasks into a unified text-to-text format where the input and output are always text strings, in contrast to BERT-style models that output only a class label or a span of the input. The base T5 model has about 220 million total parameters.
GPT family
OpenAI, an AI research and deployment company, has a mission “to ensure that artificial general intelligence (AGI) benefits all of humanity.” Of course, OpenAI hasn’t achieved AGI yet. And some AI researchers, such as machine learning pioneer Yann LeCun of Meta-FAIR, believe that OpenAI’s current approach to AGI is a dead end.
OpenAI is responsible for the GPT family of language models, which are available via the OpenAI API and Microsoft’s Azure OpenAI Service. Note that the entire GPT family is based on Google’s 2017 Transformer neural network architecture, which is legitimate because Google open-sourced Transformer.
GPT (Generative Pretrained Transformer) is a 2018 model from OpenAI that uses about 117 million parameters (see GPT paper). GPT is a unidirectional transformer that was pre-trained on the Toronto Book Corpus and was trained with a causal language modeling (CLM) objective, meaning that it was trained to predict the next token in a sequence.
GPT-2 is a 2019 direct scale-up of GPT with 1.5 billion parameters, trained on a data set of eight million web pages, or ~40 GB of text data. OpenAI originally restricted access to GPT-2 because it was “too good” and would lead to “fake news.” The company eventually relented, although the potential social problems became even worse with the release of GPT-3.
GPT-3 is a 2020 autoregressive language model with 175 billion parameters, trained on a combination of a filtered version of Common Crawl, WebText2, Books1, Books2, and English Wikipedia (see GPT-3 paper). The neural network used in GPT-3 is similar to that of GPT-2, with a couple of additional blocks.
The biggest downside of GPT-3 is that it tends to “hallucinate,” in other words make up facts with no discernable basis. GPT-3.5 and GPT-4 have the same problem, albeit to a lesser extent.
CODEX is a 2021 descendent of GPT-3 that was fine-tuned for code generation on 54 million open-source GitHub repositories. It is the model used in GitHub Copilot, which I discuss in the next section.
GPT-3.5 is a set of 2022 updates to GPT-3 and CODEX. The gpt-3.5-turbo model is optimized for chat but also works well for traditional completion tasks.
GPT-4 is a 2023 large multimodal model (accepting image and text inputs, emitting text outputs) that OpenAI claims exhibits human-level performance on various professional and academic benchmarks. GPT-4 outperformed GPT-3.5 in a number of simulated exams, including the Uniform Bar Exam, the LSAT, the GRE, and several AP subject exams.
It’s of serious concern that OpenAI hasn’t explained how GPT-4 was trained; the company says it’s for competitive reasons, which makes some sense given the competition between Microsoft (who has been funding OpenAI) and Google. Still, not knowing the biases in the training corpus means that we don’t know the biases in the model. Emily Bender’s take on GPT-4 (posted on Mastodon on March 16, 2023) is that “GPT-4 should be assumed to be toxic trash until and unless #OpenAI is *open* about its training data, model architecture, etc.”
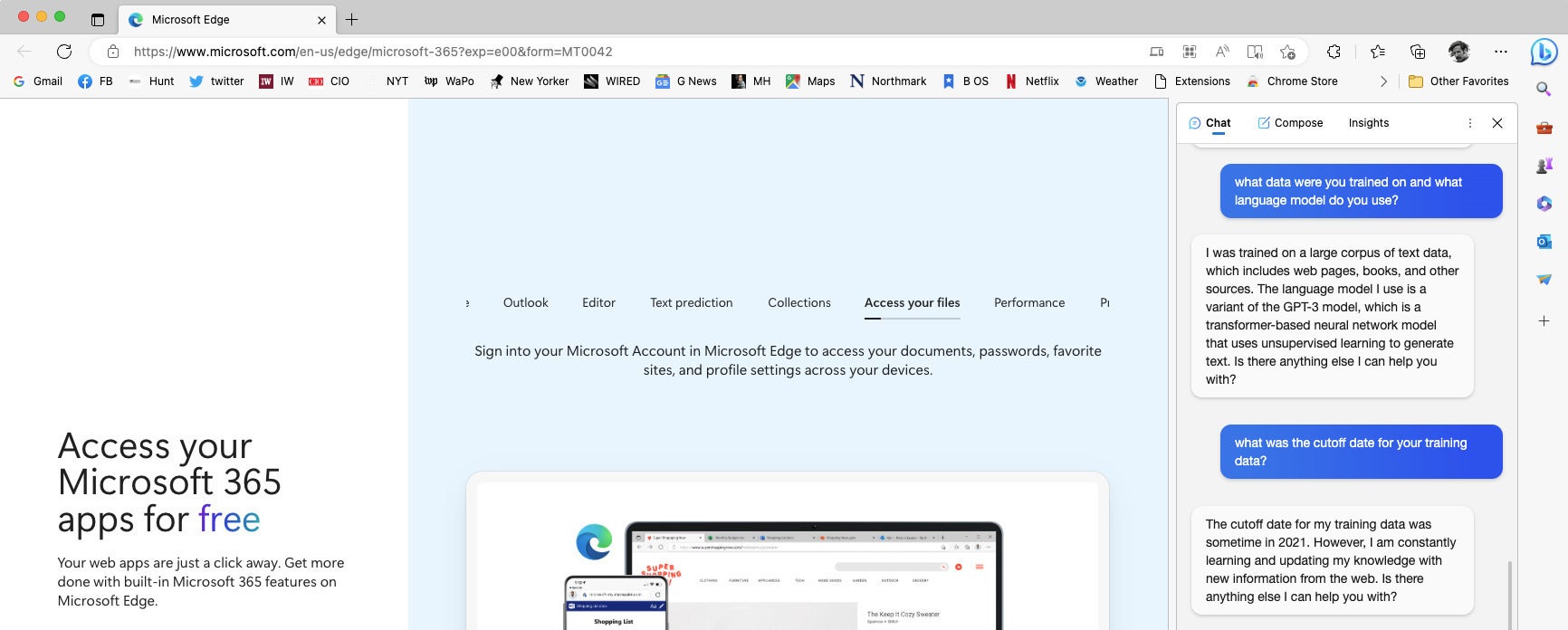
ChatGPT and BingGPT are chatbots that were originally based on gpt-3.5-turbo and in March 2023 upgraded to use GPT-4. Currently, to access the version of ChatGPT based on GPT-4, you need to subscribe to ChatGPT Plus. The standard ChatGPT, based on GPT-3.5, was trained on data that cut off in September 2021. BingGPT, which you can access in the Microsoft Edge browser, was also trained on data that cut off in 2021, but says (when you ask it) that “I am constantly learning and updating my knowledge with new information from the web.”
 IDG
IDG
BingGPT explaining its language model and training data, at the right of the image. Screenshot taken March 16, 2023.
In early March 2023, Pascale Fung of the Centre for Artificial Intelligence Research at the Hong Kong University of Science & Technology gave a talk on ChatGPT evaluation. It’s well worth spending the hour to watch it.
LaMDA
LaMDA (Language Model for Dialogue Applications), Google’s 2021 “breakthrough” conversation technology, is a 2017 Transformer model trained on dialogue, and fine-tuned to significantly improve the sensibleness and specificity of its responses. One of LaMDA’s strengths is that it can handle the topic drift that is common in human conversations.
A version of LaMDA powers Bard, Google’s conversational AI service. Bard was released March 21, 2023 and made generally available on May 10, 2023. I discuss its code generation capabilities below.
PaLM
PaLM (Pathways Language Model) is a 2022 dense decoder-only Transformer model from Google Research with 540 billion parameters, trained with the Pathways system (see PaLM paper). PaLM was trained using a combination of English and multilingual data sets that include high-quality web documents, books, Wikipedia, conversations, and GitHub code.
Google also created a “lossless” vocabulary for PaLM that preserves all whitespace (especially important for code), splits out-of-vocabulary Unicode characters into bytes, and splits numbers into individual tokens, one for each digit. PaLM-Coder is a version of PaLM 540B fine-tuned on a Python-only code data set.
PaLM-E
PaLM-E is a 2023 “embodied” (for robotics) multimodal language model from Google. The researchers began with PaLM, a powerful large language model, and embodied it (the “E” in PaLM-E) by complementing it with sensor data from the robotic agent. PaLM-E is also a generally capable vision-and-language model. In addition to PaLM, it incorporates the ViT-22B vision model.
LLaMA
LLaMA (Large Language Model Meta AI) is a 65 billion parameter “raw” large language model released by Meta AI (aka Meta-FAIR) in February 2023. According to Meta, “Training smaller foundation models like LLaMA is desirable in the large language model space because it requires far less computing power and resources to test new approaches, validate others’ work, and explore new use cases. Foundation models train on a large set of unlabeled data, which makes them ideal for fine-tuning for a variety of tasks.”
LLaMA was released at several sizes, along with a model card that details how the model was built. Originally, you had to request the checkpoints and tokenizer, but they are in the wild now, as a downloadable torrent was posted on 4chan by someone who properly obtained the models by filing a request, according to Yann LeCun of Meta-FAIR.
Specialized code generation products
While several large language models including ChatGPT and Bard can be used for code generation as released, it helps if they are fine-tuned on some code, typically from free open-source software to avoid overt copyright violation. That still raises the specter of “open-source software piracy,” which is the claim of a 2022 federal class-action lawsuit against GitHub, Microsoft (owner of GitHub), and OpenAI about the GitHub Copilot product and the OpenAI GPT Codex model.
Note that in addition to using AI models trained largely on publicly available code, some code generation tools rely on searching code-sharing sites such as Stack Overflow.
Amazon CodeWhisperer
Amazon CodeWhisperer integrates with Visual Studio Code and JetBrains IDEs, generates code suggestions in response to comments and code completions based on existing code, and can scan code for security issues. You can also activate CodeWhisperer for use inside AWS Cloud9 and AWS Lambda.
CodeWhisperer supports the Python, Java, JavaScript, TypeScript, and C# programming languages well, and another 10 programming languages to a lesser degree. It’s available free for individual developers and costs $19 per user per month for professional teams.
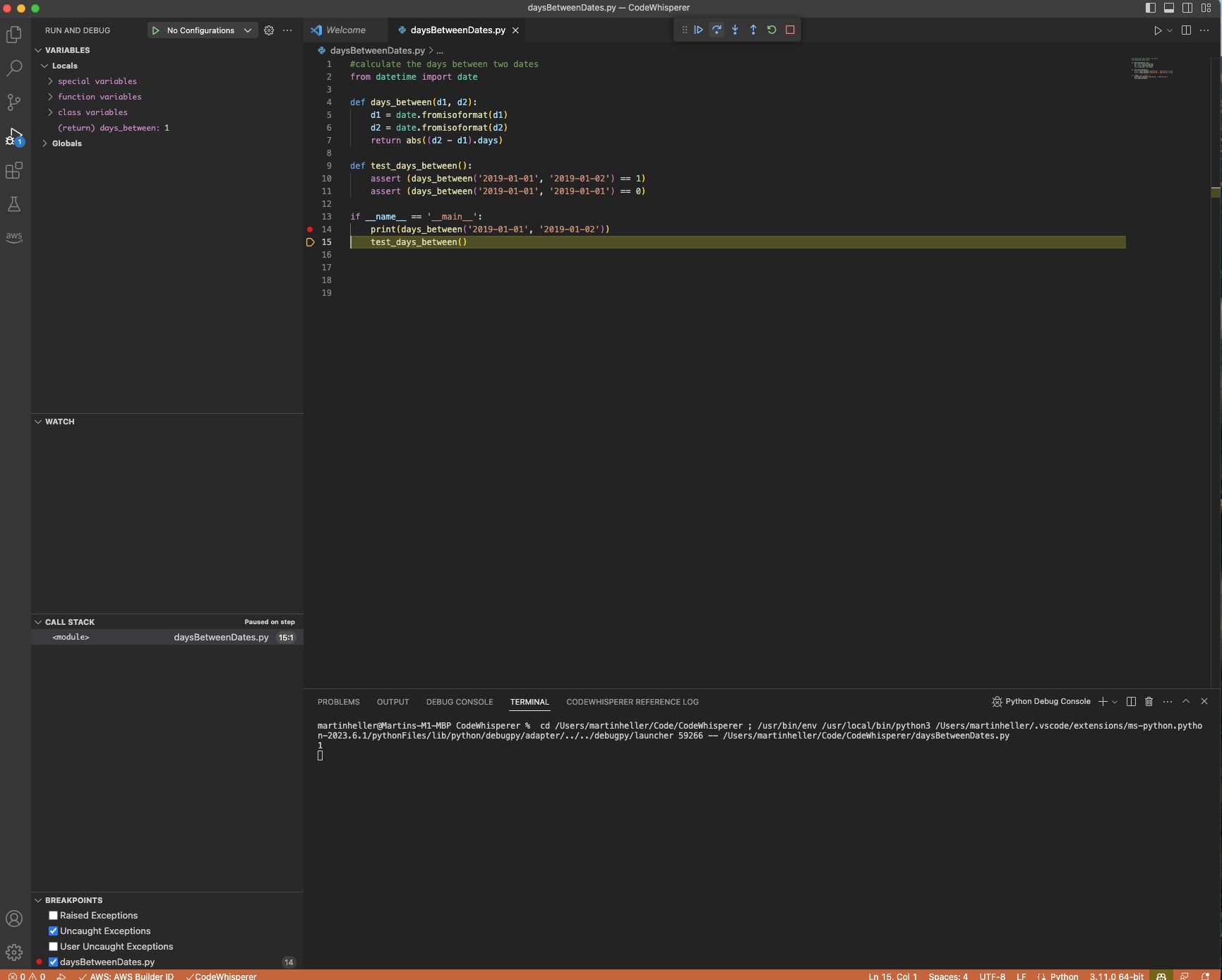
CodeWhisperer helped me to write the Python code shown below. I reviewed, tested, and debugged it, and it’s fine.
 IDG
IDG
Code generation with Amazon CodeWhisperer. I typed the comment at the top of the file, and most of the rest was CodeWhisperer. I did have to choose my code from several options and delete an unused import statement from a previous option.
Bard
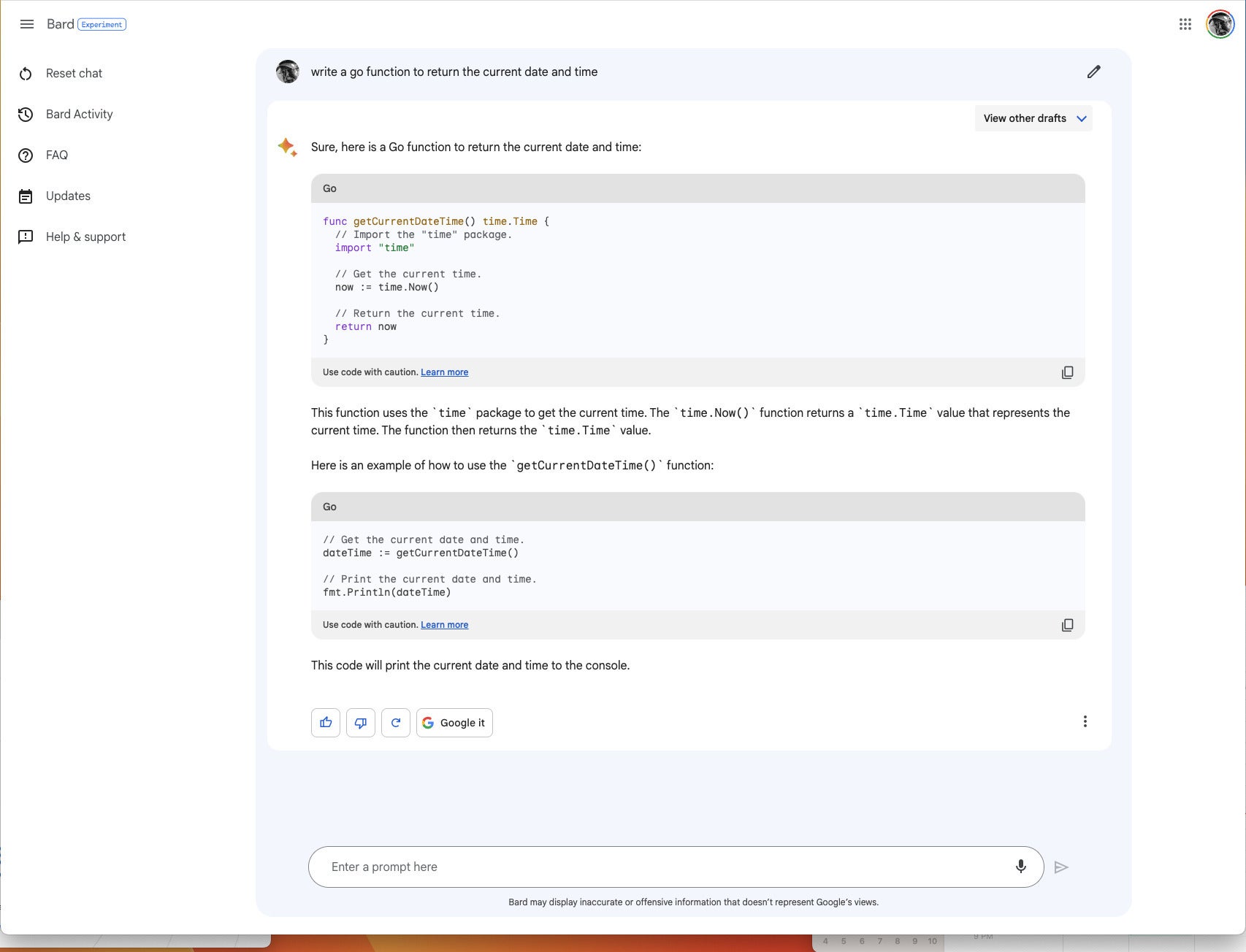
Bard support for programming was announced April 21, 2023. The announcement notes support for more than 20 programming languages including C++, Go, Java, JavaScript, TypeScript, and Python. As a quick test, I asked Bard to “write a Go function to return the current date and time.” It did so quickly:
 IDG
IDG
Bard generated a correct Go language function, an example of using the function, and an explanation of the function, all from the prompt “write a go function to return the current date and time.” Note the icons to copy the function and the test code.
Not only did Bard write the function, it also explained the function and generated an example of calling the function.